Okay – I was reminded last month that I was “old”! I was moving some couches (electric recliners) and hurt my back – who knew? I used to work for a moving company, so the doctor illustrating the proper lifting technique did not help my ego!
But, the real reason I was reminded I was old – someone asked when I started working with Oracle Real Application Clusters (RAC). Of course, RAC is the foundation and forgotten benefit of Exadata, which is seldom discussed during a cloud migration approach. However, I would like to remind people of the benefits of RAC in my second installment of my Exadata post. What you should consider when migrating from Exadata.
So yes, I am old, although I like to say “seasoned”. I started working on a pre-release of Oracle Parallel Server (OPS) with Oracle 6.0.36 at Data General. The mixture of Data General AViiON servers and CLARiiON disk arrays was a compelling platform for OPS. The “cluster wars” of 1993 between Data General, Sequent and Pyramid were awesome times and great events at Oracle Open World. But the evolution of Oracle RAC from OPS is more than remarkable and often forgotten. RAC is also a feature that is either overlooked or not discussed by most Cloud Service Provider (CSP) engineers in sizing or or migration discussions.
Before we begin, we need to make sure we are talking correctly about terms. As I have heard different terms for RAC systems. The correct terminology for RAC is “Highly Resilient System” … so here are some terms…
- Fault Tolerant System – Able to continue processing, regardless of the number of failures. No outage, connection loss or data loss.
- Fault Resilient System – Able to continue processing in the event of a single system failure (99.999% availability), including disk, network, CPU or host. In-flight transactions are failed to another system, while there is no data loss.
- High Availability System – Failover of processing in the event of a system failure. A highly available system (99.99% availability) will fail to a separate system with minimal outage and potential data loss.
Between Oracle 6.0.37 and Oracle 8, the Oracle cluster solution was about resiliency (fault resilient system). Some of these installations were a nationwide rail system and an emergency 911 system, which require high transactions with aggressive uptime requirements. However, this is a far cry from where we are now. The following bullets show the evolution of OPS to RAC and why we should question the migration of RAC environments to a non-RAC CSP.
- Oracle Parallel Server (Oracle 6.0.36 to Oracle 8): Cluster Consistency via distributed cluster locks transferred through the cluster interconnect. Individual hardware vendors provided the Distributed Lock Manager (DLM) as part of the clusterware installation.
- Oracle RAC (Oracle 9i – 11.1) – Oracle developed DLM with Parallel Cache Manager (cached locks) for cluster consistency, improved reliability and reduced lock latency (performance).
- Oracle RAC (Oracle 11.2 – present) – Oracle enhanced distributed cluster system maintaining cluster consistency and reduced data latency. Data shared between nodes through cluster interconnect to reduce storage dependency on cluster resident data.
That is 30 years of evolution, from 1993 to 2023 – I told you I was old! The evolution is simple, the RAC solution has gone from a fault resilient platform to a high-performance platform. The RAC interconnect transitioned from slowly transporting lock and cluster health information to rapidly transporting lock, health and data between nodes. The introduction of Oracle Exadata exploited the Oracle 11.2 data transfer feature with high performance interconnects.
So back to the initial question … What should you consider when migrating from Exadata? With this installment, the benefits of Oracle RAC should definitely be considered when migrating from Exadata. These benefits are scalability, performance, and application resiliency. I don’t mean to pick on people, but I have not heard correct description of benefits of Oracle RAC from a CSP engineer over the past 5 years. I contribute the misstatement of RAC benefits to lack of understanding, as I hope they are not leaving this information off on purpose.
Scalability
Unfortunately, horizontal scalability is not mentioned much during cloud migrations. Most of the database platforms focus on smaller shapes or potentially different architectures. We have seen Google Cloud Platform (GCP) produce impressive scalability with Big Query, but we experienced an impact to latency at the time of the test. So, in cases of applications and databases requiring low latency activity, Exadata provides an optimal and scalable solution.
As presented in the following diagram, we executed the same benchmark four times to a NON-EXADATA Oracle RAC system – each time adding a node to the cluster. We utilized the default settings for the SCAN (Single Client Access Network) – in other words, we did not isolate application services among nodes to reduce lock propagation. Simply out of the box, no tuning, the application continues a consistent slope between one node to four nodes providing impressive scalability. The largest difference in the configuration of our test platform and Exadata is the speed of the interconnect (10 GB/sec) and the storage access (16 GB/sec) via FiberChannel connections.
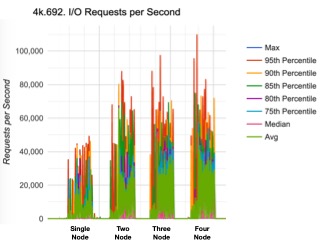
The scalability associated with RAC is difficult to achieve in a non-cluster architecture. The loosely coupled architecture of Oracle RAC integrated with the high-performance architecture of the Exadata delivers unique Oracle database performance, resiliency and scalability.
I/O Performance
The Exadata key performance indicator is throughput, measured in MBPS, which is a combination of “pipe” speed and “pipe” size. Most CSP engineers point to IOPS as a key performance indicator; however, Oracle, since Oracle 6, has focused on the reduction of IOPS through request efficiencies. These efficiencies include “piggyback writes” for non-committed transactions, read-ahead for sequential transactions and others. Most storage array providers still include read-ahead optimizations for database transactions – also reducing the reported number of IOPS. With the implementation of Exadata off-loading to storage cells, the IOPS reporting is not a valid reporting measure for database / system performance requirements. Leveraging Oracle’s efficiencies with requests per second, the throughput provides a more realistic resource requirement for performance.
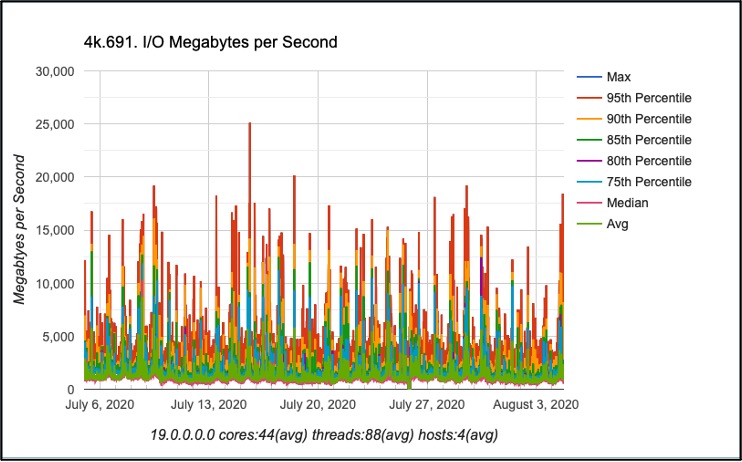
The following graph represents the throughput requirements for a half-rack Exadata X7 supporting a client’s data warehouse. While the average throughput hovers around 3.5 GB/second there are some considerable spikes for 15GB/second throughput and above.
One of the challenges of performance is reporting. Most Oracle performance analysis is performed through AWR reports provided by the client over a period of time. Most CSP engineers consider these reports as gospel, as they don’t understand the data provided. The Oracle AWR report provides a glimpse of the workload for “health” reasons but does not provide beneficial reporting for workload sizing or analysis. The reason is simple, the AWR report averages the data for all “peaks” and “valleys” based on the duration of the report.
The AWR report for the same system and same timeline above paints a totally different picture of the resource requirements for throughput. The following graph presents the data provided by an AWR report, representing the same 3.5GB/second average, but totally misleading the 15GB/second peak to show a 5 – 8 GB/second throughput requirement. Why is this so misleading? The duration of the AWR report is 30 days and the “collection” reporting interval is limited to minute data points. Therefore, there are less data points presented over a considerable period, represented as a smooth graph on the report.
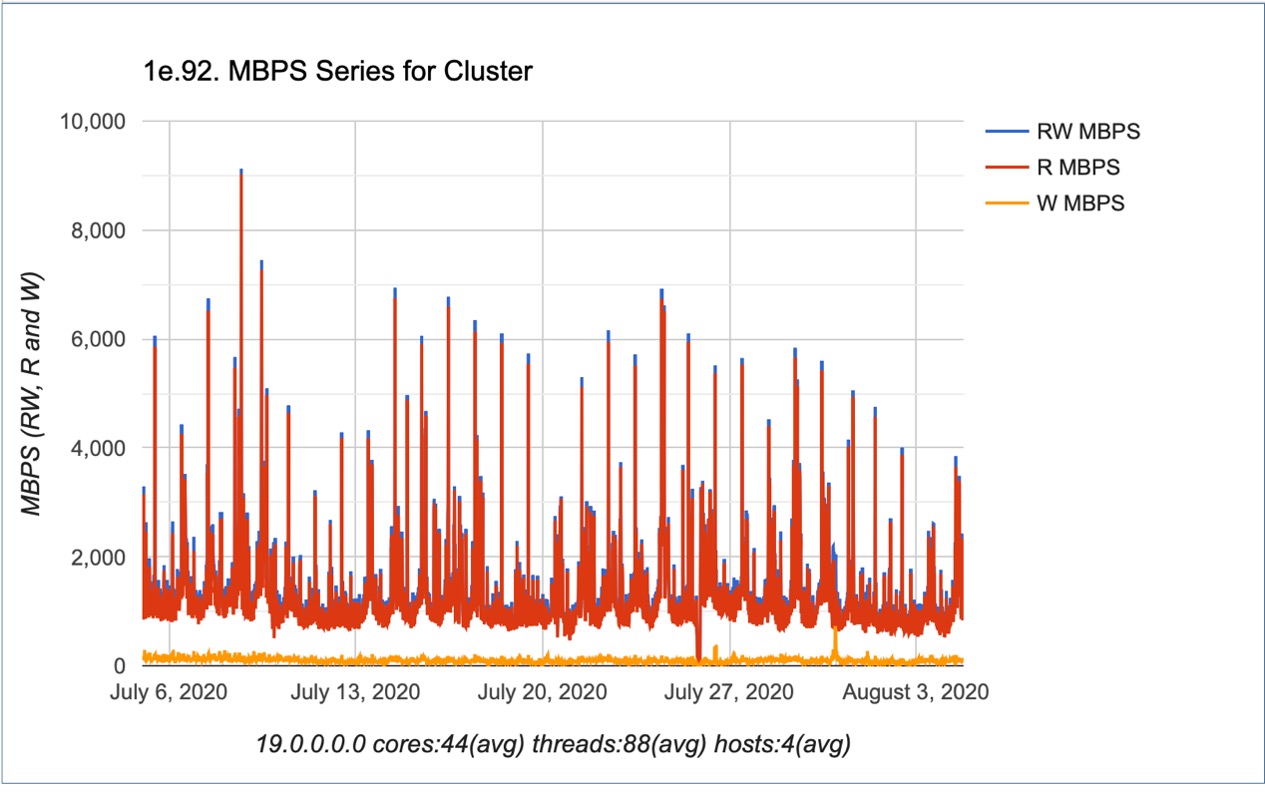
There are two primary take-away on I/O performance and Oracle workloads. First, throughput (MBPS) is the key performance indicator – NOT bandwidth (IOPS). This is because Oracle optimizes IO to reduce “requests” and increase data flow. Second, reporting is important for workload sizing and analysis. While an AWR report is good for trends and optics, it is not sufficient when presenting Exadata workloads targeted for non-Exadata environments.
Interconnect Performance
But, what about RAC? Remember, this is the goal of this discussion and how does RAC factor with performance? Among other things, RAC performance is greatly dependent on the interconnect, which is a private network between the compute nodes. In the early days, the interconnect supported the cluster locking processes and cluster heartbeat. However, with the introduction of the Exadata and Oracle 11.2, the implementation and functionality of the interconnect changed.
The introduction of InfiniBand for storage and interconnect, the RAC interconnect became a transport for data. Monitoring RAC implementations, there is now more traffic on the interconnect. The following graph presents the interconnect traffic on a half-rack Exadata, which has four (4) compute nodes.

The spikes and dynamic throughput provided indicates more than just lock traffic traversing through the interconnect. As more data is sent and received by nodes, the impact on storage systems also becomes evident.
On a recent engagement, a three (3) node RAC environment based on commodity hardware was experiencing issues. Through analysis, I observed a few things:
- The environment was experiencing very high IO waits for the number of active sessions. Due to the density of application schemas in multiple databases (small database footprint), the IO wait time spikes are consistent on all databases within the associated cluster – as well as databases on other clusters. [This is a standard consolidation configuration on Oracle, which is not bad – but there are limitations]
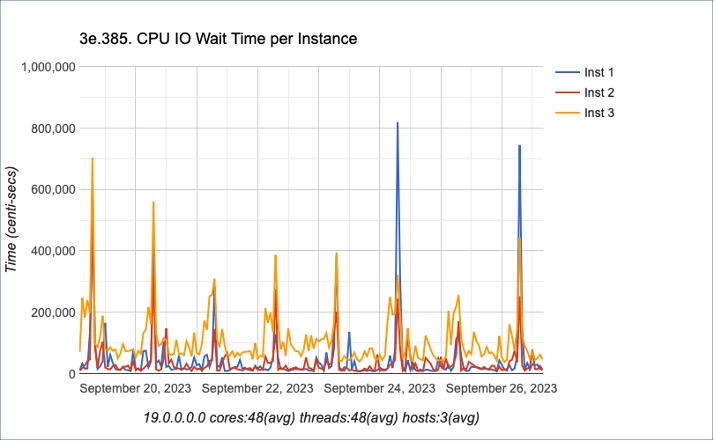
- The amount of traffic traversing the interconnect correlates with the IO activity on the cluster. The following graph shows the interconnect activity spike prior to IO waits on disk. Potentially, the request from alternative instances occurs prior to IO transactions to disk.
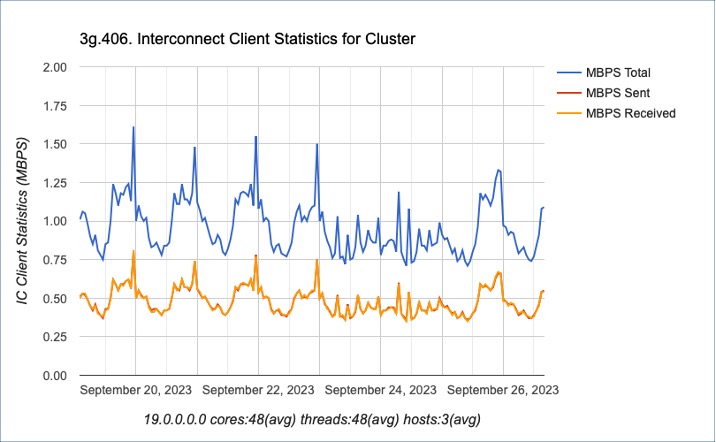
As the following graph presents, the IO requests occur after activity is performed by the interconnect. Some of this is standard locking processes; however, there is additional activity and data traffic that occurs. As you can see, IO activity begins shortly after the interconnect spikes. I will want to investigate it more, but my hypothesis is the interconnect activity occurs first – prior to going to disk. This is consistent with NUMA features and I am making the assumption the cluster process remains consistent.
Summary
As detailed above, the implementation of RAC consists of 20+ years of evolution to get where we are now. Although most CSP engineers like to frame RAC as a High Availability system, the reality is that RAC is a fault resilient platform with performance features included. These performance features resemble a NUMA architecture where the Parallel Cache is interrogated prior to an IO request – thus reducing IO contention and leveraging a faster interconnect.
As Oracle continues to perform as a consolidation platform, both on-premises and in the cloud, it is important to note these features. The consolidation of schema reduces the reliance on CPU; however, ensure the IO features are available. As indicated, the Exadata platform provides a distributed IO platform built to reduce incoming and outgoing IO processing. These are features not available in a general cloud service provider – such as Azure or AWS. While some features of Google are general cloud, I also consider Google a specialized cloud platform, such as Oracle cloud, for large data volumes with Big Query and other features.
As more things move to cloud, my recommendation is to improve application and data agility. This includes reducing the number of application schema per database – which allows the client the decision to move to the appropriate cloud based on data requirement and governance. I am a huge fan of distributed data and data mesh architectures, which leverage the best technology to the client domain. Therefore, understanding application and data architecture is more than a simple infrastructure decision.








 This is a picture of my bike, in my house “torture chamber”. I can guarantee that it is more complicated than just getting on and peddling!
This is a picture of my bike, in my house “torture chamber”. I can guarantee that it is more complicated than just getting on and peddling!