In a previous life, we were engaged by an account team to support a cloud architecture and migration. Our challenge: the cloud destination and application were decided before an analysis of requirements or capability. Since the underlying architecture included Oracle and Oracle Real Application Clusters (RAC), our team was engaged for the migration effort. In the initial discussion with the client team, they were not able to describe the application requirements or the client’s resiliency requirements.
Our initial discovery uncovered the client legacy environment included multiple two-node Oracle Real Application Cluster (RAC) configurations connected geographically by Oracle GoldenGate. The Oracle GoldenGate implementation supported an ACTIVE/ACTIVE implementation between the two Oracle RAC deployments. The two connected Oracle RAC environments support the primary web portal supporting a large population of the client connections. The following diagram presents the legacy environment prior to the cloud migration.
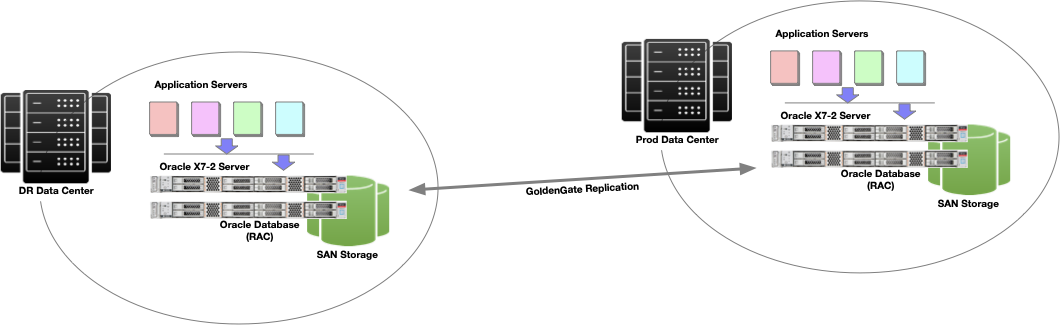
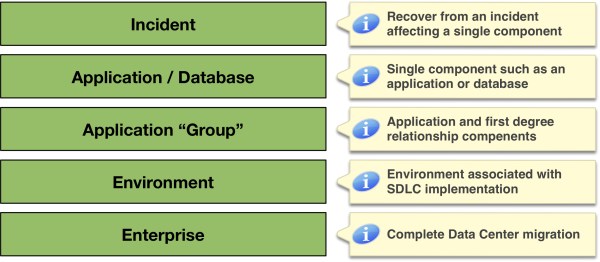
Resilient RAC Environment
The implementation characteristics infer an emphasis on system/application availability. The ACTIVE/ACTIVE implementation of Oracle GoldenGate enabled a low latency transition in the event of environment failure. The dual node Oracle RAC systems were deployed for resiliency, not throughput. This architecture represents a majority of the non-engineered systems RAC installations configured for high availability. We easily deduced the client’s focus was on availability, followed by throughput – which was verified during our first client discussion.
Unfortunately, the pre-selected cloud target did not provide the technical capability to support the resiliency and agility requirements of the application installation. The goal of the account team and the cloud team was to get to the cloud first, then figure out the details. While I won’t get into the details of the solution architecture and migration process, I wanted to share my opinion to the effort. Unfortunately, “move to the cloud first and analyze later” is a common approach with most account teams, which is when we get involved to save a failing project.
The focus on this “cloud first approach” represents a transactional cloud strategy effort. Each individual transaction represents a single major event, including migration, performance tuning, resiliency deployment. The migration transaction would consist of successfully moving the data from an on-premises environment to a cloud destination.
… This is the same as purchasing a vehicle and the sales manager hands you the keys, but they don’t provide the vehicle. …
There is more to an application than putting data in the cloud, so much more!
Additional transactions, such as resiliency and performance, are not considered. Quite often, this afterthought leads to failures due to poor performance or system outages. The following diagram represents an actual situation we were engaged after a migration occurred to a popular cloud provider.
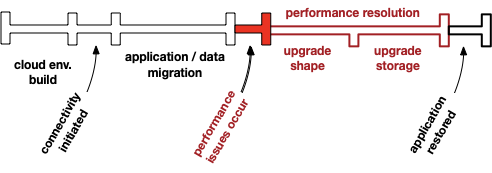
Transactional Cloud Strategy example
In other situations, the performance issue is replaced with a system failure. However, in all occurrences, the impact to the client is the same. These impacts include prolonged outages, cost increases to cloud solution and lost confidence from client business units. In some cases, the client reverses the current and future cloud initiatives.
The unfortunate difference between a transactional cloud strategy and a relational cloud strategy is repetition. A transactional cloud strategy means a single transaction is potentially repeated multiple times for the same application due to ignored transactions. These missed requirements commonly include resiliency or performance requirements, impacting the functionality of the application and application experience. The relational cloud strategy focuses on the long-term impact of a solution. Therefore, the relational cloud strategy includes the review of the current resource utilization, client requirements and client projections for defining a strategic cloud provisioning plan.
I learned a strategic methodology combines years of experience and effective tools for defining a strategic cloud implementation. The experience includes more than 30 years of infrastructure and Oracle deployments focused on resiliency and performance. Utilizing a tool suite that includes open-source tools developed in collaboration of many Oracle experts for analyzing, engineering and provisioning. The following diagram represents a standard cloud engagement focused on relational cloud strategy.
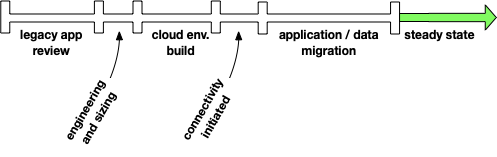
Relational Cloud Strategy
The relational cloud strategy focuses on build right and migrate once, which is a strategic implementation. The focus not only includes resiliency and performance, but also agility. Providing an architecture focused on standard patterns and procedures supports application requirements. A strategic implementation ensures system available and stable cost models.
Eliminating the “redo transactions”, the
Relational Cloud Strategy
enables the focus on business, not on redo efforts.